大綱
method
documen.links可以得到所有的<a> 連結
//method 1
var allLinks = document.links;
for (var i=0; i<allLinks.length; i++) {
document.write(allLinks[i].href+"<BR/>");
}
method 2
document.links 也可以用另外一個通用函數getElementByTagName()取代。
//method 2
var links = document.getElementsByTagName('a');
for(var i = 0; i< links.length; i++){
alert(links[i].href);
}
練習
下面程式碼會有甚麼結果,觀察href 在哪裡。
//method 2 (error) only for object properties ?
//例如,如果urls是一個物件,則url 是urls的一個欄位?
var urls=document.links;
for (url in urls){
console.log(url.innerHTML);
}
example
//demo
// in google search r markdown pdf
var x=document.getElementsByTagName("a");
for (var i=0;i< x.length;i++){
var url=x[i].href ; //innerHTML,outerHTML
if(/\.pdf$/.test(url)){
console.log(url);
}
//var p=RegExp('*\.pdf').exec();
}
search,match
stringObj.match(rgExp)
如果 match 方法找不到符合的項目,會傳回 null。 如果找到符合的項目,則 match 方法會傳回一個陣列,然後更新全域 RegExp 物件的屬性來反映符合的結果。
如果未設定全域旗標 (g),陣列的元素 0 會包含整個相符項目,而元素 1 至 n 則包含任何子相符項目。 此行為相當於不設定全域旗標的 exec 方法 (規則運算式)。 如果設定全域旗標,元素 0 至 n 就會包含所有的相符項目。
全域,例如 ("stri").match('/com/g') 全域搜尋'com'。
如果不是全域(內定):則傳回第一個找到的子字串。傳回的陣列有兩個屬性:input 和 index。 input 屬性包含整個搜尋的字串。 index 屬性包含相符子字串在整個搜尋字串中的位置。如下 ["com", index: 22, input: "https://stackoverflow.com/"] 0:"com" index:22 input:"https://stackoverflow.com/" length:1
如果設定旗標 i,則搜尋不區分大小寫。
在下列程式碼中,說明了如何使用 match 方法。
var src = "azcafAJAC";
var re = /[a-c]/;
var result = src.match(re);
// 只找了第一個符合的,所以在陣列0號.
document.write(result[0] + "<br/>");
// Now try the same match with the global flag.
var reg = /[a-c]/g;
result = src.match(reg);
// The matches are in elements 0 through n.
for (var index = 0; index < result.length; index++)
{
document.write ("submatch " + index + ": " + result[index]);
document.write("<br />");
}
課堂練習
先用chrome 搜尋"javascript",然後F12開啟偵錯環境。 分別看下面程式的執行結果: 1) 【比較1】
var urls=document.links;
for (i=0;i<3;i++){
d=urls[i].href.match('com');
console.log(d);
console.log(urls[i].href.search('com'));
}
結果
["com", index: 22, input: "https://stackoverflow.com/"]0: "com"index: 22input:
["com", index: 22, input: "https://stackoverflow.com/jobs?med=site-ui&ref=jobs-tab"]
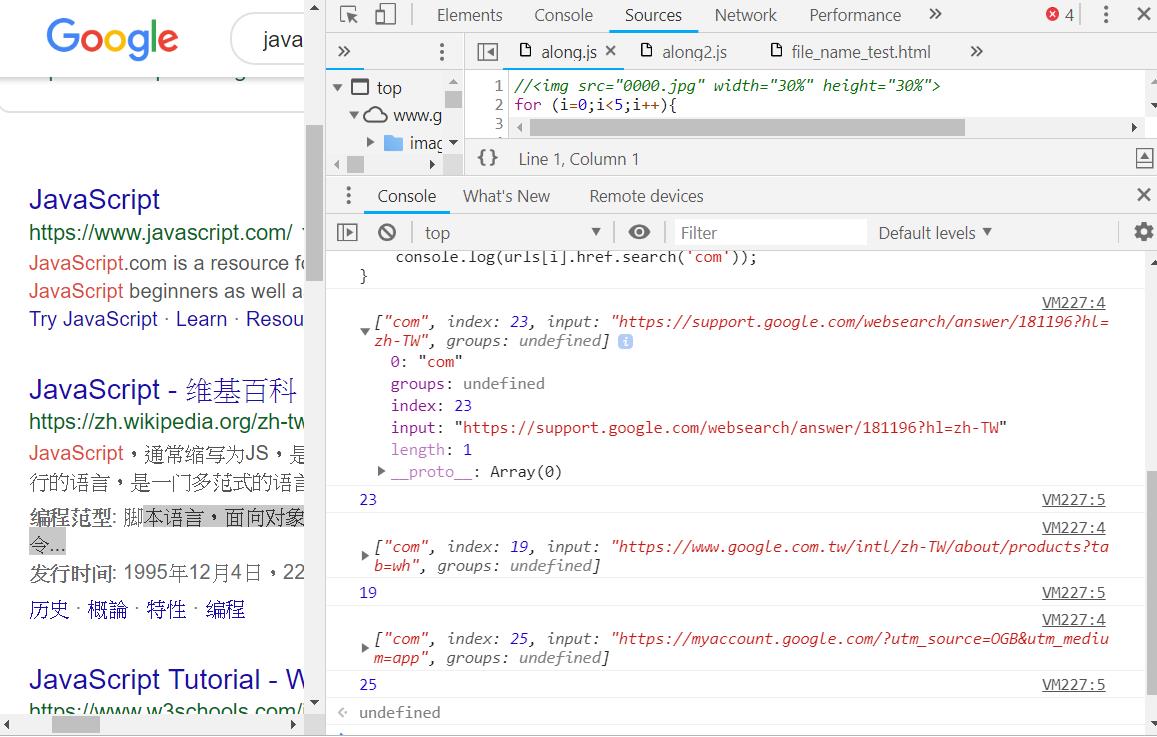 【比較2】參考上圖,和比較2程式碼第3行
【比較2】參考上圖,和比較2程式碼第3行d=urls[i].href.match('com')[0]; 可以知道上圖的結果只是把一個list內容顯示為字串的結果:
其中[0]標籤,的內容為一個字串com,也就是搜尋到的內容。
其中[index]標籤: 則是位置。
var urls=document.links;
for (i=0;i<3;i++){
d=urls[i].href.match('com')[0];
console.log(d);
console.log(urls[i].href.search('com'));
}
結果
com 22 com 22
下載網頁中所有的pdf
var links = document.getElementsByTagName('a');
// Do this selection based on your table
for(var count=0; count<links.length; count++) {
var url = links[count].getAttribute('href');
if(url && url.endsWith('.pdf')) {
links[count].dispatchEvent(new MouseEvent('click'));
}
}
note: chrome://plugins 關掉在chrome 中顯示pdf
將所有連結下載
在chrome snippet 中測試,OK
var downloadFile = function(sUrl) {
var link = document.createElement('a');
link.href = sUrl;
if (link.download !== undefined){
//Set HTML5 download attribute. This will prevent file from opening if supported.
var fileName = sUrl.substring(sUrl.lastIndexOf('/') + 1, sUrl.length);
link.download = fileName;
}
//Dispatching click event.
if (document.createEvent) {
var e = document.createEvent('MouseEvents');
e.initEvent('click' ,true ,true);
link.dispatchEvent(e);
return true;
}
// Force file download (whether supported by server).
var query = '?download';
window.open(sUrl + query);
}
var allLinks = document.links;
for (var i=0; i<allLinks.length; i++) {
downloadFile(allLinks[i].href);
}